
Back in 2015, Yahoo! shut down a service I used to love called Yahoo Pipes. It allowed you to combine and filter XML-based RSS feeds to create a new RSS feed containing the data you wanted.
At the time, I looked for a decent alternative and didn’t find anything.. until I realised that Logic Apps (a Microsoft Azure resource) were actually comparable to a next-gen version of Yahoo Pipes, with A LOT more functionality.
Since Logic Apps / Power Automate (used to be called Flow) is a lot more feature-rich, it does mean it’s initially a little harder to do what you want with the data, but once you’ve developed a few, you’ll see how much more flexible they are, especially when the world has moved to JSON-based APIs, with XML-based RSS taking a backseat.
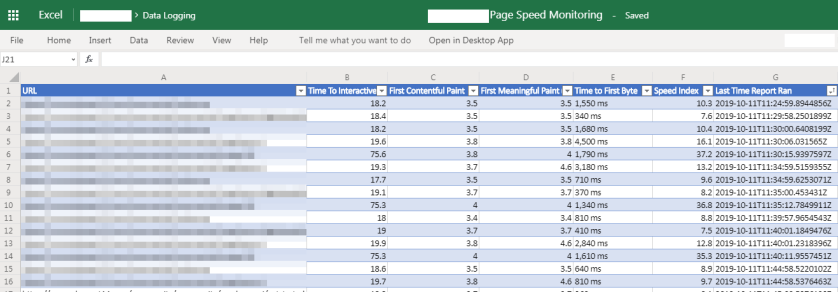
While Pipes would just output RSS, Logic Apps can output the result into pretty much anything you want.. JSON, email, other APIs, Twitter, spreadsheets (Office 365 and Google Sheets).. the list goes on and on!
You can get started with Logic Apps for free.. and they’re very low cost to run beyond the Azure trial period. You’re talking pennies to run them monthly, depending on run-frequency & complexity. The pricing calculator can help you if you’re worried about cost. If you created 10 Logic Apps, each containing 10 basic actions and 10 standard actions, and ran them all once a day for 30 days it’d cost you 34p a month;

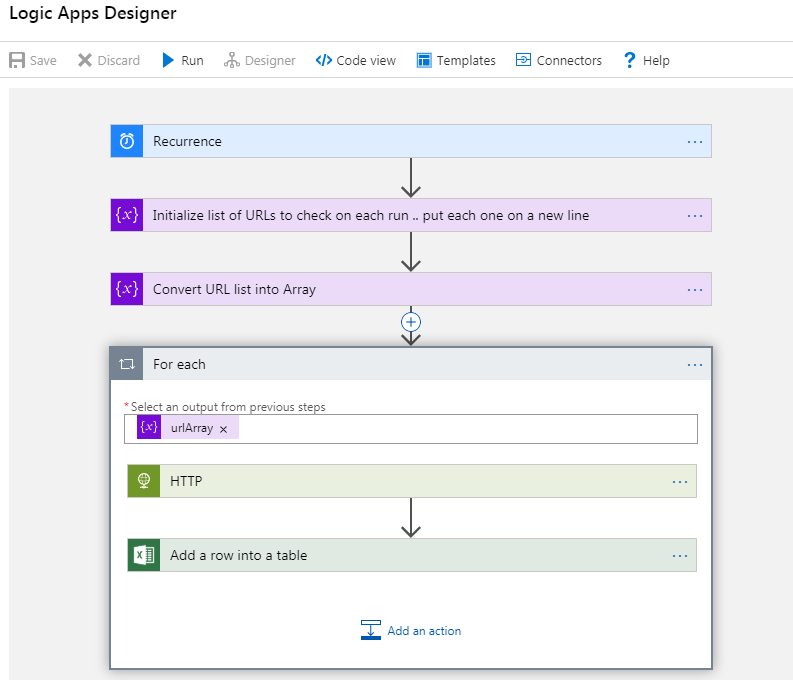
Actions in Logic Apps are the blocks you see in a flow;

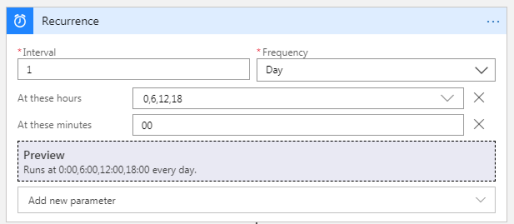
It starts with a ‘Trigger’.. so in this case I’ve chosen a Recurrence (schedule), but you could set one up to trigger on a HTTP call from an RSS reader app, something happening on Twitter, or pretty much anything.. here’s a few of the triggers to choose from…

Non-Microsoft products are well represented, so don’t go thinking you’re limited to SharePoint or Office 365, that’s not the case.
You then design the flow how you want it to behave, e.g. get data from X and Y, merge it together, filter it, query an API, persist some data in a sheet, then send back a piece of JSON.
Choose from Built-In, Standard or Enterprise actions.. you can even build your own custom connectors for systems that aren’t currently listed.

As you’ll see in the video I put together, to replace Yahoo Pipes, you need to be able to merge, filter, manipulate, and sort JSON. You can do a lot of this with the built-in actions, but you can use Inline Code to achieve anything else.
Inline Code runs NodeJS and has access to standard built-in JavaScript objects.
The one thing that’s Logic Apps aren’t great for compared to Yahoo Pipes is sharing what you’ve created.. it was really easy to adapt what someone else made to suit your needs. Logic Apps don’t work like that at all, and you’ll need to roll your own, which takes some trial-and-error & patience.
Basic filtering (etc) is quite straightforward …

… but Inline Code might take you longer to figure out, so to get you started, here are some Inline Code snippets you might find useful;
Simple Text Filter
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| const filtered = workflowContext.actions.Current_JSON.outputs.filter(item => item.display_name=='My search string'); | |
| return filtered; |
Multi-Filter Example Including Regex
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var titles = workflowContext.actions.Filter_array_on_year.outputs.body; | |
| var newTitles = []; | |
| const regex = /(.*)(2019|2020|2021).*/i; // Regex for year filtering | |
| titles.forEach(function(item) { | |
| // Additional filter for titles containing 1080p only | |
| if (item.title.indexOf('1080p') > -1) { | |
| // Extract the title and year only | |
| var titleMatch = regex.exec(item.title); | |
| if (titleMatch!=null && titleMatch.length>0) { | |
| var tidyTitle = titleMatch[1]+titleMatch[2]; | |
| var pubDay = item.pubdate.substr(5, 2); // Get the day number | |
| tidyTitle = pubDay + " – " + tidyTitle; | |
| // Simple dedupe | |
| if (!newTitles.includes(tidyTitle)) newTitles.push(tidyTitle); | |
| } else { | |
| newTitles.push(item.title); | |
| } | |
| } | |
| }); | |
| return newTitles; |
Generate HTML for an Email
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var titles = workflowContext.actions.Execute_JavaScript_Code.outputs.body; | |
| var html = ''; | |
| titles.forEach(function(fulltitle) { | |
| var title = fulltitle.substr(5); // Strip off the first 5 characters.. '12 – Headline' becomes 'Headline' | |
| html += fulltitle + | |
| ' | <a href="https://www.somesite.com/find?q='+title+'">Somesite</a>' + | |
| ' | <a href="https://anothersite.net/search/'+title+'">Another</a>' + | |
| '<br>'; | |
| }); | |
| html += '<br><br>Footer of email goes here'; | |
| return html; |
This hasn’t been a step-by-step guide, but has hopefully shown you enough to spark your interest.. get yourself a free trial of Azure, and give it a go!





 QR Codes are a useful way of getting data to your mobile phone using it’s built-in camera. They’re basically 2D barcodes that can carry things like URLs and contact details. On Android I’d recommend using the app called
QR Codes are a useful way of getting data to your mobile phone using it’s built-in camera. They’re basically 2D barcodes that can carry things like URLs and contact details. On Android I’d recommend using the app called 




You must be logged in to post a comment.